Copyright 2025 © All rights Reserved. Design by Elementor

Am 3. April 2025 fand das 42. Webseminar #CEresearchNRW statt. Forscher und Doktorand Jakob Deich vom Institute for Technologies and Management of Digital Transformation der Bergischen Universität Wuppertal erläuterte in seinem Vortrag wie man semantische Systeme und vor allem Large Language Model für die Umsetzung des Digitalen Produktpasses nutzen kann.
Zu Beginn gab David Rohrschneider (HRW) von der Fachgruppe Indikatorik und Digitaler Produktpass des Circular Performer Emscher-Lippe Projektes einen kurze Übersicht über den Digitalen Produktpass. Die Frage, die sich auch die Fachgruppe immer wieder stellt ist: Wie kann man feststellen, ob ein Unternehmen oder ein Produkt zirkulärer geworden ist? Wie kann dies fassbar und messbar gemacht werden?
Ein wichtiges Instrument dafür ist der digitale Produktpass, der von der EU Kommission für einen großen Teil des EU Marktes nach und nach eingeführt wird. Doch wie genau der Digitale Produktpass umgesetzt werden soll, ist noch nicht vollends festgelegt. Eine Möglichkeit ist die Nutzung von QR Codes, denen Daten über die Produkte hinterlegt werden, die z.B. für den Reparatur oder Recycling Prozess wichtig sind. So wird eine höhere Transparenz entlang der gesamten Wertschöpfungskette hergestellt. David Rohrschneider erklärte, dass im CirPEL Projekt der Fokus vor allem darauf liegt Unternehmen bei der Einführung des Produktpasses zu unterstützen. Denn oft mangelt es an der nötigen Datenkompetenz, um den Produktpass umzusetzen.
Daten sind überall. Es gibt zahlreiche Orte und Bereiche, in denen zu jeder Zeit neue Daten erstellt werden. Typische Beispiele sind z.B. Unternehmen, aber auch Smart Cities, oder natürlich Forschungsinstitute. Neben den verschiedenen Datenorten gibt es auch zahlreiche verschiedene Akteure, die mit diesen Daten und Informationen arbeiten.
Hierbei lassen sich laut Deich vor allem zwei Akteursgruppen voneinander unterscheiden. Zunächst gibt es die Datenanbieter. Diese besitzen und erstellen die Daten und sie haben detailliertes Fachwissen über ihre Daten und Informationen. Sie kennen die verschiedensten Anwendungsfälle, in denen ihre Daten und Informationen angewendet werden können.
Darüber hinaus gibt es die Datenkonsumenten. Diese möchten die Daten oder Informationen nutzen. Jedoch müssen die Datenkonsumenten zunächst die richtigen Daten für ihren Anwendungsfall finden. Dabei ist aber noch nicht klar, ob der Zugriff schon gewährleistet ist, oder ob die Daten für den Konsumenten überhaupt verständlich sind. Es liegt also eine große Wissenslücke zwischen den Datenanbieter und -konsumenten vor.
Die Probleme die aus dieser Wissenslücke resultieren können, hängen mit der Heterogenität und Mehrdeutigkeit von Daten zusammen. Daten können ganz unterschiedlich angeordnet sein, z.B. hierarchisch oder relational und können ganz unterschiedliche Formate haben z.B. (JSON, PDF, CSV, XML). Die Anwendungsfälle für die der Datenkonsument, die Daten benötigt sind darüber hinaus ebenfalls sehr divers. Ein weiteres Problem ist die heterogene Semantik: Damit der Datenkonsument, die Daten wirklich verstehen kann, muss die Semantik klar sein. Wenn ein Datensatz aus den USA Informationen über die Temperatur beinhaltet, bedeutet die Zahl fünf etwas anderes als die Zahl fünf in einem europäischen Datensatz, da den Zahlen die unterschiedlichen Maßeinheiten Fahrenheit und Celsius zu Grunde liegen.
Wie kann der Datenkonsument die Daten verstehen und interpretieren, wenn ihm nicht alle Informationen über die Einheiten oder Erklärungen zu den Daten vorliegen? Wenn er nicht weiß was hinter Abkürzungen steckt? Eine Möglichkeit wäre zum Beispiel, dass zum Datensatz ein Text verfasst wird, der den Datensatz erläutert. Aber auch hierzu müssen erst einmal grundlegende Dinge geklärt werden. Wenn nicht festgelegt wurde in welcher Sprache der Datensatz beschrieben und erläutert wird, kann der Datenkosument, die Daten eventuell trotz vorliegender Erläuterung nicht verstehen.
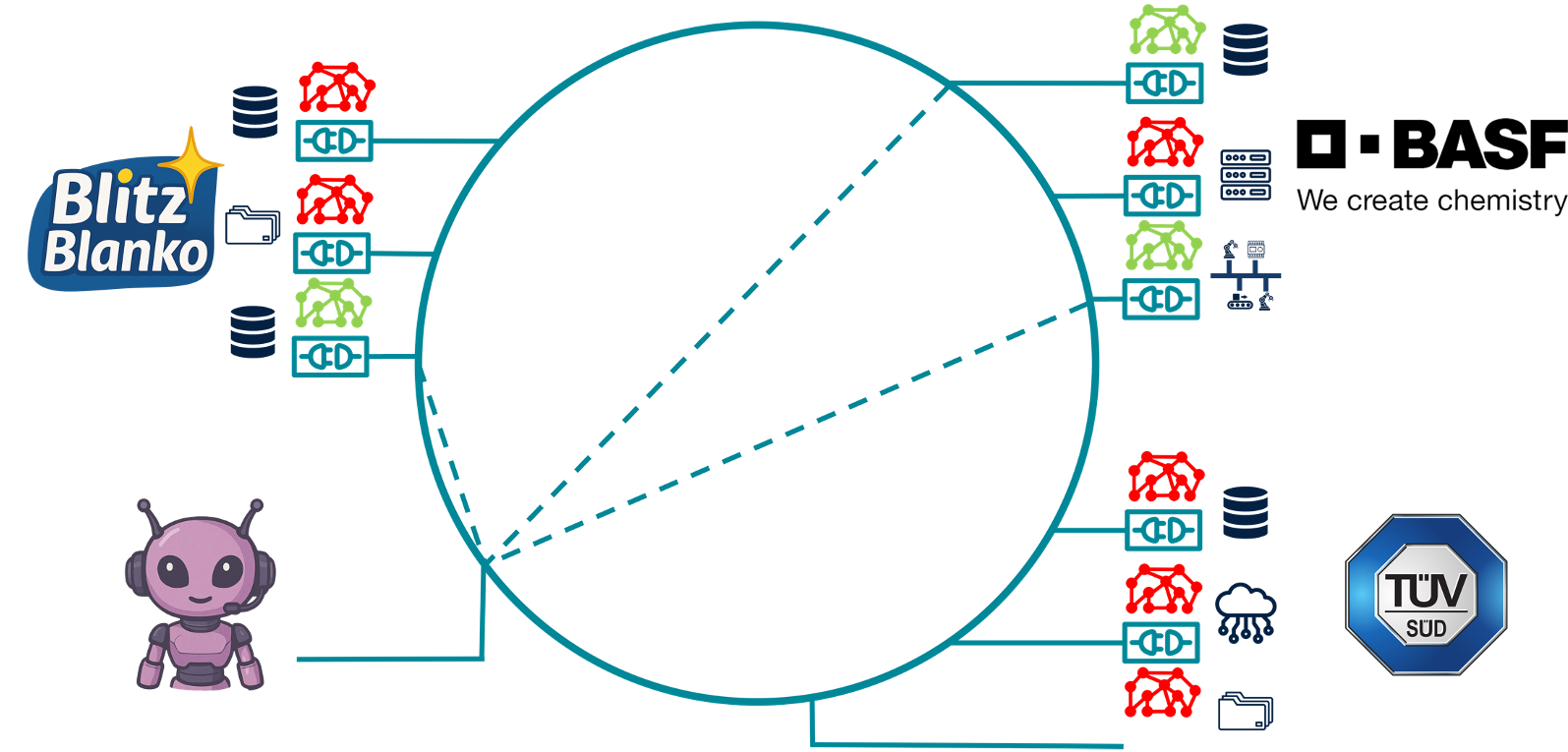
Während ein menschlicher Datenkonsument mit der Erläuterung der Daten in Schriftform gut umgehen kann, ist eine solche Beschreibung aus Sicht einer Maschine nicht oder nur schwer lesbar. An dieser Stelle setzt das semantische Datenmanagement an. Hier wird statt einer textbasierten Lösung auf eine Ontologie basierte Lösung zurückgegriffen. In der Informatik beschreibt eine Ontologie eine formale Darstellung eines Wissensgebiets, in der die relevanten Konzepte und Beziehungen zwischen ihnen beschrieben werden. Was im Ontologie basierten Ansatz passiert, ist also dass ein Mapping zwischen den Datenattributen und der Ontologie stattfindet. Wenn man sich diesen Ansatz bildlich vorstellen möchte, stehen an erster Stelle die Datensilos, die Daten sammeln, wie z.B. Unternehmen oder Forschungsinstitutionen. Insgesamt liegt all diesen Daten eine globale Ontologie zu Grunde. Um die Daten des Datensilos dann sinnvoll zu beschreiben und zuzuordnen, wird eine Teilmenge der Gesamtontologie genutzt. Diese Teilontologie macht es möglich zu verstehen, was die Daten aussagen.
Für den Digitalen Produktpass kann dieser Ansatz sehr sinnvoll sein. Jakob Deich veranschaulichte dies an einem kurzen Anwendungsbeispiel. Hierfür kreierte er das kleine mittelständische Familienunternehmen Blitz Blanko – ein Hersteller für Waschmittel – das nun dazu aufgerufen ist für sein neues Produkt Super Soft einen digitalen Produktpass bereitzustellen. Der Sohn der Familie, Boris, ist für die digitale Infrastruktur und das Datenmanagement des Unternehmens zuständig. Jedoch hat Boris leider nur wenig Datenkompetenz und ist mit seiner Aufgabe überfordert.
Um Boris zu unterstützen und seine fehlende Datenkompetenz auszugleichen arbeiten Jakob Deich und seine Kolleg*innen an der App DINa, dem Data Insight Navigator. Boris möchte den CO2 Fußabdruck seines Produktes Super Soft ermitteln. Hierzu benötigt er zunächst die Bill of Materials.
Wenn er diese Anfrage an DINa richtet, durchsucht sie die Ontologie nach passenden Matches. DINa basiert grundlegend auf einem Large Lange Model – wie man es z.B. in Form von ChatGPT kennt. Sie ist also ein Chatbot der das Wissen von vortrainierten großen Sprachmodellen nutzt. Dann überprüft DINa, das Boris auch die Zugriffsberechtigung für die angeforderten Daten hat. Es ist wichtig, dass jedes Unternehmen die Datenhoheit über seine Daten behält. Wenn die Zugriffsberechtigung erfolgt, werden die Daten in Rohform extrahiert und für Boris bereitgestellt. Da alle geforderten Daten vom Unternehmen Blitz Blanko stammen, ist dies kein Problem.
Im folgenden Schritt möchte Boris auch die CO2 Anteile der Bestandteile von Super Soft ermitteln. Der Ablauf erfolgt wie die erste Anfrage an DINa, nur das diesmal auch externe Daten des Chemieherstellers BASF benötigt werden. Diese müssen also zunächst für Boris freigegeben werden. Sobald Boris die Daten erhält, kann er den CO2 Fußabruck erstellen und die Daten in den Digitalen Produktpass von Super Soft einpflegen.
Jakob Deich und seine Kolleg*innen wollen DINa in das Projekt DACE integrieren, was für Datenkompetenzzentrum für Circular Economy Daten steht. In diesem Projekt wird ein Datenraum bereitgestellt, der Daten zugänglich macht und darüber hinaus datenbasierte Kreislaufwirtschaftsbewertungen enthält. DINa verbindet diese zwei Bausteine des DACE miteinander. Eins der ersten Beispiele an dem dies durchgespielt wurde ist die Holzspanplatte. Im Projekt Timber Connect wurde die gesamte Lieferkette einer Holzspanplatte abgebildet. Ziel war es zu erreichen, dass an jeder Stelle der Lieferkette Daten eingespeist werden können und der DPP ausgelesen werden kann. Hierbei stand nicht die optimierteste Darstellung im Vordergrund, sondern eine möglichst vollständige Darstellung. Die Hauptaufgabe von DINa soll sein, dass Daten automatisiert abrufbar sind, was vor allem für KMU mit geringer Datenkompetenz eine großer Erleichterung ist.
Zum Abschluss seines Vortrages beantwortet Jakob Deich noch zahlreiche Fragen zu seiner Forschung, den Unterschieden zu Konkurrenzprodukten und der Verknüpfung mit Large Language Model.
Wir hoffen, dass Sie auch beim nächsten #CEresearchNRW Webseminar dabei sein werden. Dieses wird ausnahmsweise am 2. Donnerstag des Monats stattfinden: am 8.5.2025 zu dem spannenden Thema “Bioökoomie trifft Circular Economy”.
Bis dahin, ihr CirPEL und Prosperkolleg e.V. Team